Benchmarking FADVI with other methods on Single-Cell Immune Atlas
This notebook demonstrates how to use FADVI for integrating single-cell RNA-seq data and compare its performance with other integration methods.
Set up and data loading
[1]:
import os
import sys
import matplotlib
import scvi
import pandas as pd
import numpy as np
import scanpy as sc
import matplotlib.pyplot as plt
import scib
from scib_metrics.benchmark import Benchmarker
from fadvi import FADVI
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
2025-09-23 10:36:06.048110: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:485] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
2025-09-23 10:36:06.060771: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:8454] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
2025-09-23 10:36:06.064374: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1452] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
2025-09-23 10:36:06.872065: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
[2]:
adata = sc.read_h5ad('data/immune_cell_atlas.h5ad')
adata
[2]:
AnnData object with n_obs × n_vars = 329762 × 29335
obs: 'soma_joinid', 'dataset_id', 'assay', 'assay_ontology_term_id', 'cell_type', 'cell_type_ontology_term_id', 'development_stage', 'development_stage_ontology_term_id', 'disease', 'disease_ontology_term_id', 'donor_id', 'is_primary_data', 'self_reported_ethnicity', 'self_reported_ethnicity_ontology_term_id', 'sex', 'sex_ontology_term_id', 'suspension_type', 'tissue', 'tissue_ontology_term_id', 'tissue_general', 'tissue_general_ontology_term_id', 'n_genes', 'batch', 'size_factors'
var: 'soma_joinid', 'feature_id', 'feature_name', 'feature_length', 'n_cells', 'hvg', 'hvg_score'
uns: 'dataset_description', 'dataset_id', 'dataset_name', 'dataset_organism', 'dataset_reference', 'dataset_summary', 'dataset_url', 'knn', 'normalization_id', 'pca_variance'
obsm: 'X_pca'
varm: 'pca_loadings'
layers: 'counts', 'normalized'
obsp: 'knn_connectivities', 'knn_distances'
[3]:
adata.obs['cell_type'].value_counts()
[3]:
cell_type
naive thymus-derived CD4-positive, alpha-beta T cell 37613
memory B cell 30124
CD8-positive, alpha-beta memory T cell 25519
classical monocyte 21847
CD16-positive, CD56-dim natural killer cell, human 20591
effector memory CD4-positive, alpha-beta T cell 19869
alveolar macrophage 17238
CD4-positive helper T cell 16099
T follicular helper cell 15293
effector memory CD8-positive, alpha-beta T cell, terminally differentiated 14612
naive B cell 13998
CD8-positive, alpha-beta memory T cell, CD45RO-positive 12674
regulatory T cell 12143
gamma-delta T cell 11577
CD16-negative, CD56-bright natural killer cell, human 8902
naive thymus-derived CD8-positive, alpha-beta T cell 7801
plasma cell 6270
alpha-beta T cell 5631
macrophage 4938
mucosal invariant T cell 4849
animal cell 4413
lymphocyte 3584
mast cell 3291
non-classical monocyte 2420
plasmablast 1710
progenitor cell 1518
conventional dendritic cell 1503
group 3 innate lymphoid cell 1312
plasmacytoid dendritic cell 713
germinal center B cell 572
erythroid lineage cell 445
megakaryocyte 317
dendritic cell, human 262
precursor B cell 75
pro-B cell 39
Name: count, dtype: int64
[4]:
adata.obs['batch'].value_counts()
[4]:
batch
D496 88057
D503 79004
640C 35527
637C 25843
A36 24105
A29 17327
A31 12446
582C 11590
A35 11105
621B 10632
A37 9806
A52 4320
Name: count, dtype: int64
We set the cell type labels in half batches to unknown for semi-supervised learning.
[5]:
half_batches = pd.unique(adata.obs['batch'])[0:len(pd.unique(adata.obs['batch']))//2]
adata.obs['cell_type_with_unknown'] = adata.obs['cell_type'].astype(str)
adata.obs.loc[adata.obs.batch.isin(half_batches),'cell_type_with_unknown'] = 'Unknown'
We select 2000 highly variable genes for batch integration.
[6]:
idx = adata.var["hvg_score"].to_numpy().argsort()[::-1][:2000]
adata = adata[:, idx].copy()
adata.X = adata.layers['normalized']
del adata.layers['normalized']
adata
[6]:
AnnData object with n_obs × n_vars = 329762 × 2000
obs: 'soma_joinid', 'dataset_id', 'assay', 'assay_ontology_term_id', 'cell_type', 'cell_type_ontology_term_id', 'development_stage', 'development_stage_ontology_term_id', 'disease', 'disease_ontology_term_id', 'donor_id', 'is_primary_data', 'self_reported_ethnicity', 'self_reported_ethnicity_ontology_term_id', 'sex', 'sex_ontology_term_id', 'suspension_type', 'tissue', 'tissue_ontology_term_id', 'tissue_general', 'tissue_general_ontology_term_id', 'n_genes', 'batch', 'size_factors', 'cell_type_with_unknown'
var: 'soma_joinid', 'feature_id', 'feature_name', 'feature_length', 'n_cells', 'hvg', 'hvg_score'
uns: 'dataset_description', 'dataset_id', 'dataset_name', 'dataset_organism', 'dataset_reference', 'dataset_summary', 'dataset_url', 'knn', 'normalization_id', 'pca_variance'
obsm: 'X_pca'
varm: 'pca_loadings'
layers: 'counts'
obsp: 'knn_connectivities', 'knn_distances'
Batch integration
Wrapper functions from scib package are called to perform batch integration. The latent representations are saved in adata.obsm.
[7]:
method_integration = {'Harmony':scib.ig.harmony, 'Combat':scib.ig.combat, 'scVI':scib.ig.scvi, 'scANVI':scib.ig.scanvi }
emb_list = {}
for name, method in method_integration.items():
adata_input = adata.copy()
if name == 'scANVI':
adata_output = method(adata_input, batch="batch", labels="cell_type")
else:
adata_output = method(adata_input, batch="batch")
if name == 'Combat':
scib.pp.reduce_data(adata_output, batch_key="batch", pca=True, neighbors=False)
emb_list[name] = adata_output.obsm['X_pca']
else:
emb_list[name] = adata_output.obsm['X_emb']
for name, emb in emb_list.items():
adata.obsm[name] = emb
Initialization is completed.
Completed 1 / 10 iteration(s).
Completed 2 / 10 iteration(s).
Completed 3 / 10 iteration(s).
Reach convergence after 3 iteration(s).
/data/wliu12/miniconda3/envs/rnew/lib/python3.12/site-packages/scanpy/preprocessing/_combat.py:347: RuntimeWarning: divide by zero encountered in divide
(abs(g_new - g_old) / g_old).max(), (abs(d_new - d_old) / d_old).max()
HVG
Using 2000 HVGs from full intersect set
Using 0 HVGs from n_batch-1 set
Using 2000 HVGs
Computed 2000 highly variable genes
PCA
/data/wliu12/miniconda3/envs/rnew/lib/python3.12/site-packages/scanpy/preprocessing/_pca/__init__.py:438: FutureWarning: Argument `use_highly_variable` is deprecated, consider using the mask argument. Use_highly_variable=True can be called through mask_var="highly_variable". Use_highly_variable=False can be called through mask_var=None
warn(msg, FutureWarning)
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
You are using a CUDA device ('NVIDIA RTX 6000 Ada Generation') that has Tensor Cores. To properly utilize them, you should set `torch.set_float32_matmul_precision('medium' | 'high')` which will trade-off precision for performance. For more details, read https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html#torch.set_float32_matmul_precision
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [1]
/data/wliu12/miniconda3/envs/rnew/lib/python3.12/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:433: The 'train_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=63` in the `DataLoader` to improve performance.
`Trainer.fit` stopped: `max_epochs=24` reached.
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [1]
/data/wliu12/miniconda3/envs/rnew/lib/python3.12/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:433: The 'train_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=63` in the `DataLoader` to improve performance.
`Trainer.fit` stopped: `max_epochs=24` reached.
INFO Training for 8 epochs.
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [1]
/data/wliu12/miniconda3/envs/rnew/lib/python3.12/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:433: The 'train_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=63` in the `DataLoader` to improve performance.
`Trainer.fit` stopped: `max_epochs=8` reached.
FADVI training: supervised.
Batch-corrected label representation is saved in adata.obsm[“FADVI”], and batch representation is saved in adata.obsm[“FADVI_batch”].
[8]:
FADVI.setup_anndata(adata, batch_key="batch",labels_key="cell_type",
unlabeled_category='Unknown', layer="counts")
model = FADVI(adata, n_latent_l=30, n_latent_b=30, n_layers=2, lambda_b = 50, lambda_l = 50)
model.train(30, batch_size=200)
adata.obsm["FADVI"] = model.get_latent_representation(representation="l")
adata.obsm["FADVI_batch"] = model.get_latent_representation(representation="b")
adata.obsm["FADVI_residual"] = model.get_latent_representation(representation="r")
model.save("scvi_save/immune_atlas", save_anndata=True, overwrite=True)
INFO Training for 30 epochs.
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [1]
/data/wliu12/miniconda3/envs/rnew/lib/python3.12/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:433: The 'train_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=63` in the `DataLoader` to improve performance.
`Trainer.fit` stopped: `max_epochs=30` reached.
FADVI training: semi-supervised.
[9]:
FADVI.setup_anndata(adata, batch_key="batch",labels_key="cell_type_with_unknown",
unlabeled_category='Unknown', layer="counts")
model = FADVI(adata, n_latent_l=30, n_latent_b=30, n_layers=2, lambda_b = 50, lambda_l = 50)
model.train(30, batch_size=200)
adata.obsm["FADVI(semi)"] = model.get_latent_representation(representation="l")
adata.obsm["FADVI(semi)_batch"] = model.get_latent_representation(representation="b")
adata.obsm["FADVI(semi)_residual"] = model.get_latent_representation(representation="r")
model.save("scvi_save/immune_atlas_semi", save_anndata=True, overwrite=True)
INFO Training for 30 epochs.
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [1]
/data/wliu12/miniconda3/envs/rnew/lib/python3.12/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:433: The 'train_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=63` in the `DataLoader` to improve performance.
`Trainer.fit` stopped: `max_epochs=30` reached.
FADVI training: unsupervised.
FADVI can be run in an unsupervised manner, but its performance will be lower than semi-supervised.
Here we create a dummy variable and use it as label instead of cell types. In this case the label classifier is redundant so we set the coefficient (lambda_l) of label classification loss to 0.
We cannot disentangle label variation and residual variant, so the final latent representation should be only splitted into batch-specific (representation=”b”) and label+residual (representation=”lr”).
[10]:
adata.obs['dummy'] = 'dummy'
FADVI.setup_anndata(adata, batch_key="batch",labels_key="dummy",
unlabeled_category='Unknown', layer="counts")
model = FADVI(adata, n_latent_l=30, n_latent_b=30, n_layers=2, lambda_b = 50, lambda_l = 0)
model.train(30, batch_size=200)
adata.obsm["FADVI(un)"] = model.get_latent_representation(representation="lr")
adata.obsm["FADVI(un)_batch"] = model.get_latent_representation(representation="b")
model.save("scvi_save/immune_atlas_un", save_anndata=True, overwrite=True)
INFO Training for 30 epochs.
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [1]
/data/wliu12/miniconda3/envs/rnew/lib/python3.12/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:433: The 'train_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=63` in the `DataLoader` to improve performance.
`Trainer.fit` stopped: `max_epochs=30` reached.
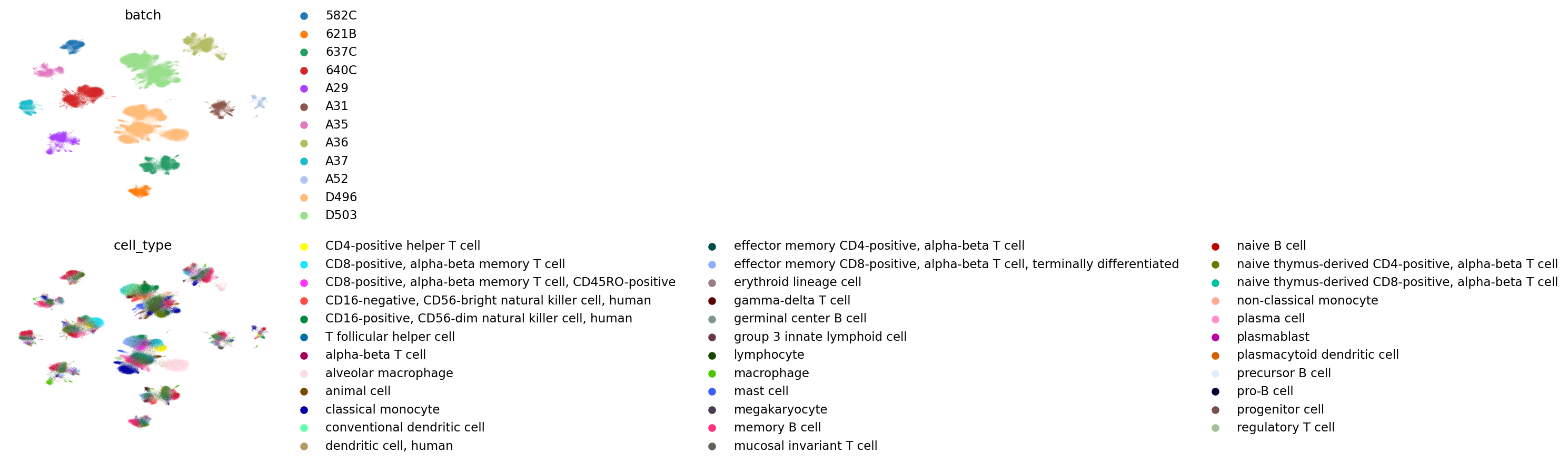
UMAP visualization
[11]:
for emb_i in list(method_integration.keys()) + ["FADVI","FADVI(semi)","FADVI(un)","FADVI_batch","FADVI(semi)_batch","FADVI(un)_batch"]:
print(emb_i)
sc.pp.neighbors(adata, use_rep=emb_i)
sc.tl.umap(adata, key_added=f'X_umap_{emb_i}')
sc.pl.embedding(
adata, basis=f'X_umap_{emb_i}',
color=["batch","cell_type"], #
frameon=False,
ncols=1,
)
Harmony
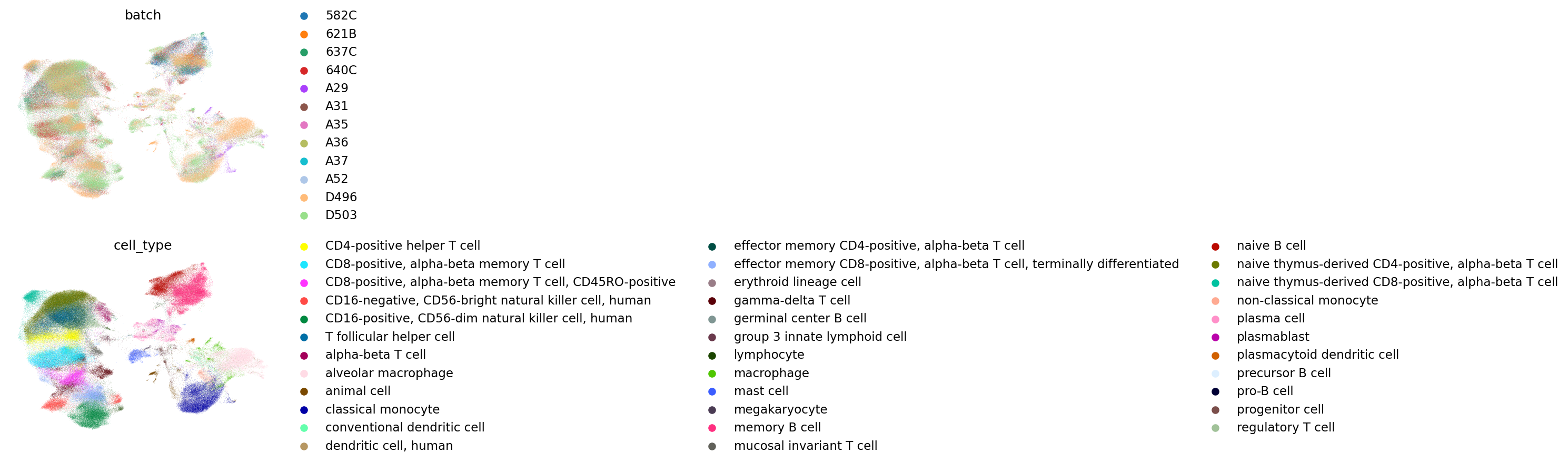
Combat
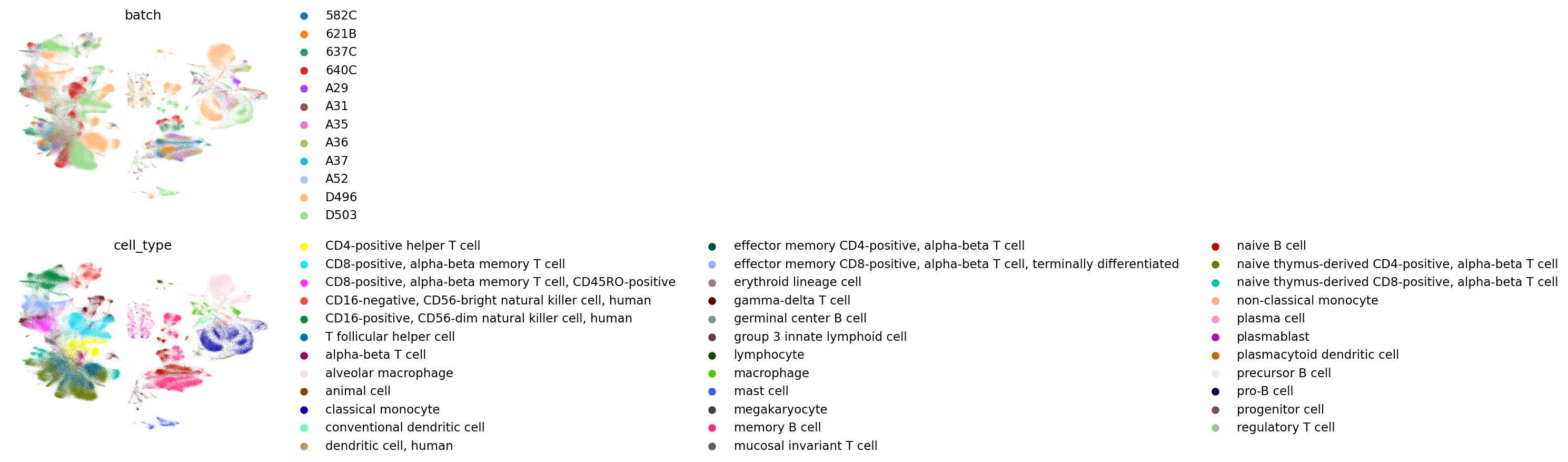
scVI
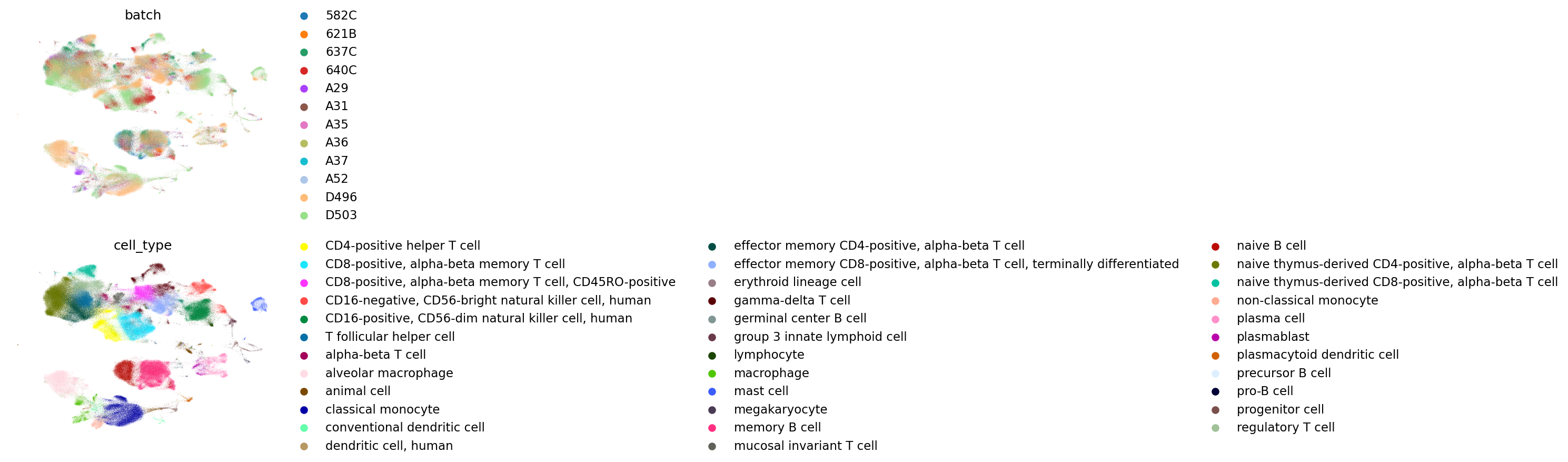
scANVI
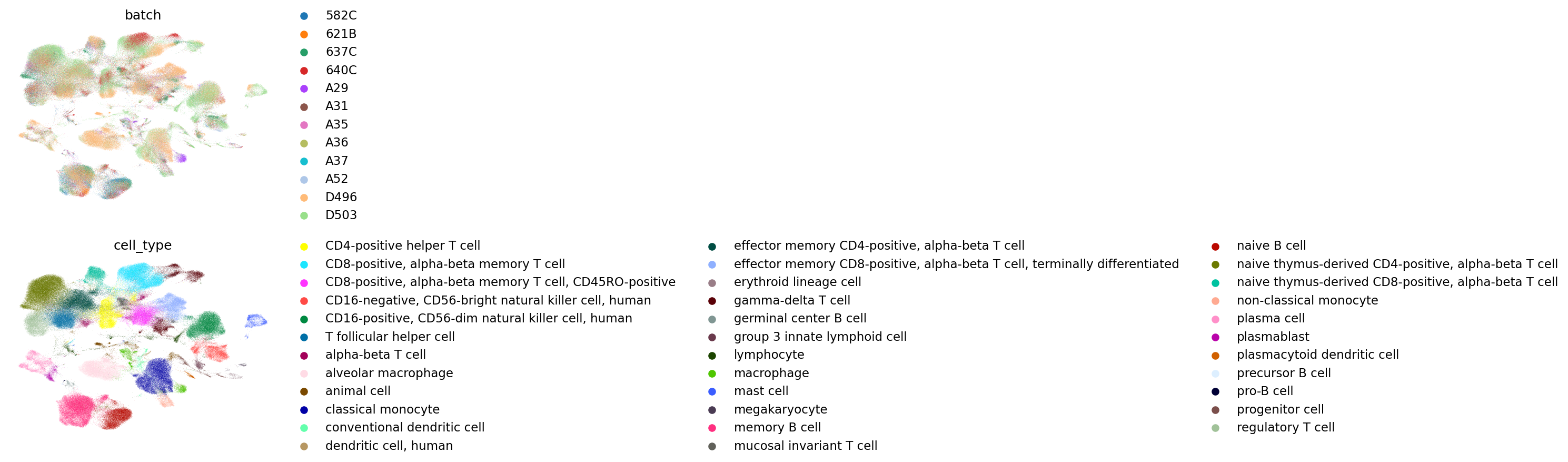
FADVI
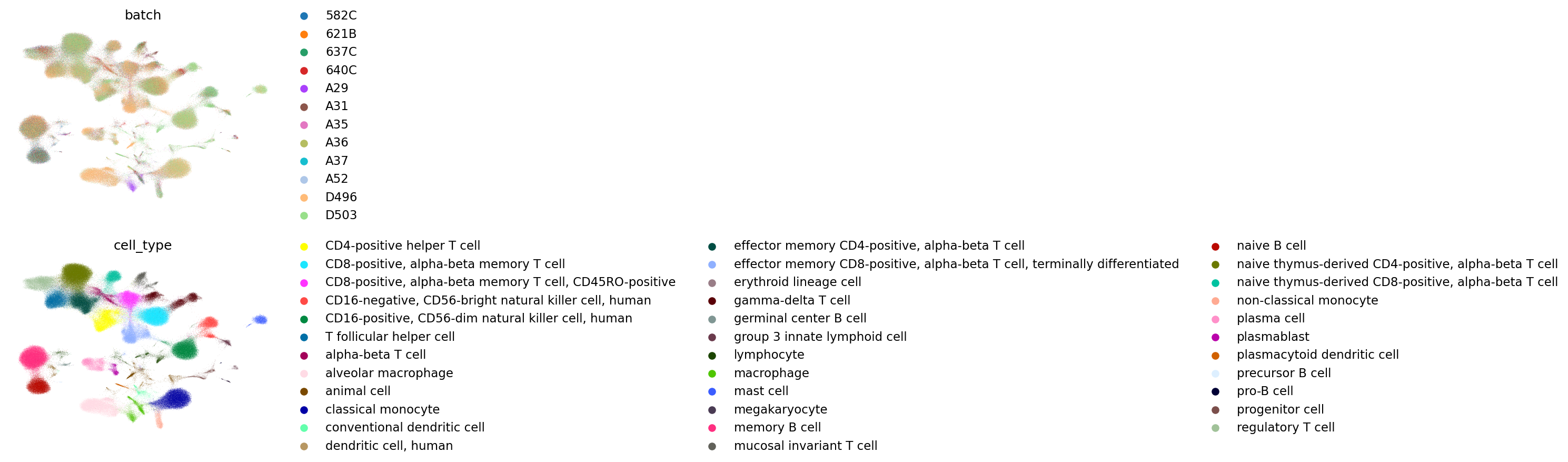
FADVI(semi)
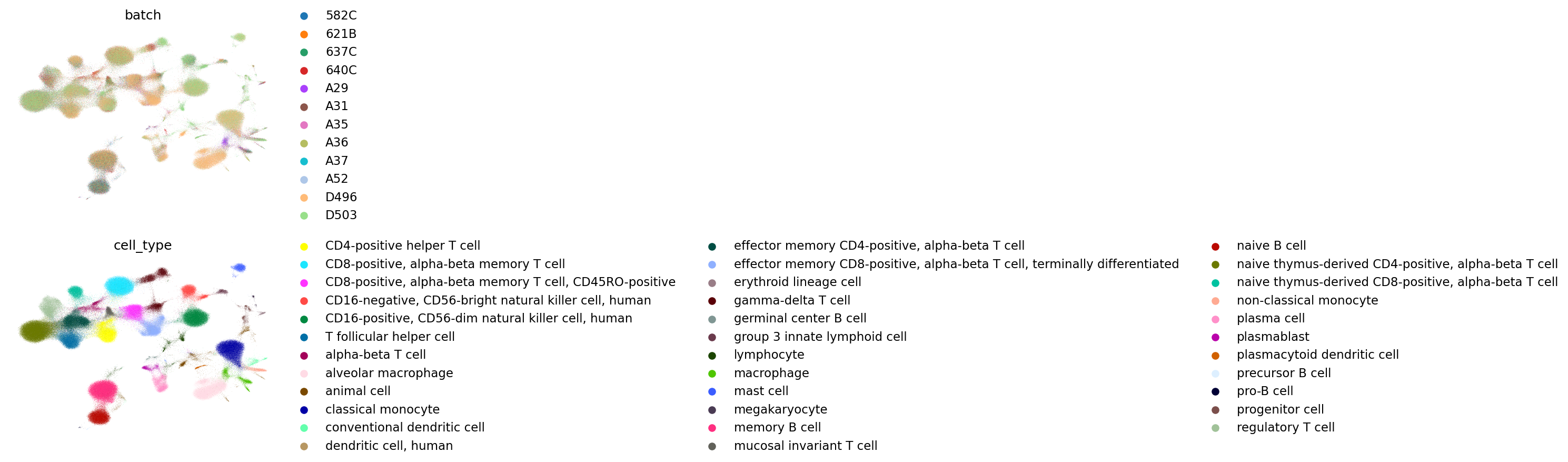
FADVI(un)
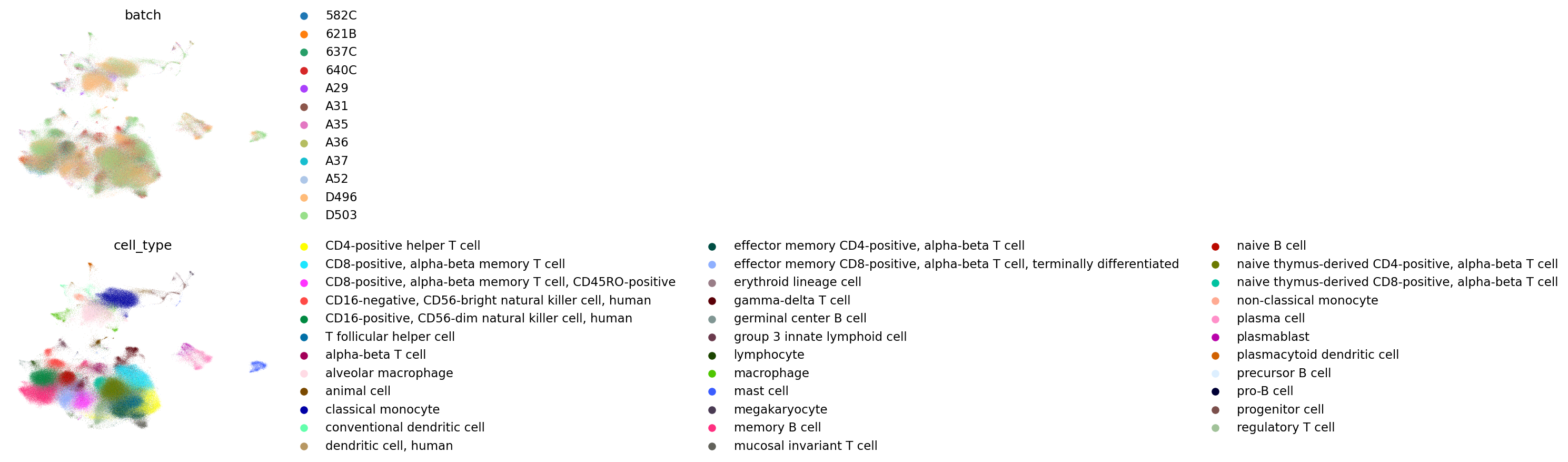
FADVI_batch
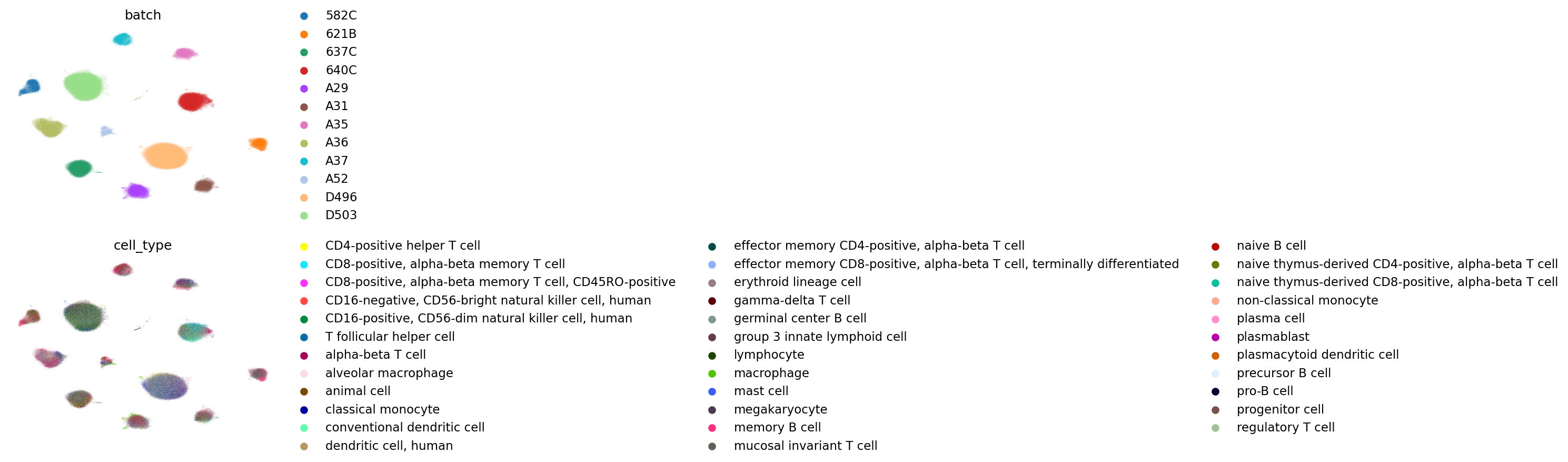
FADVI(semi)_batch
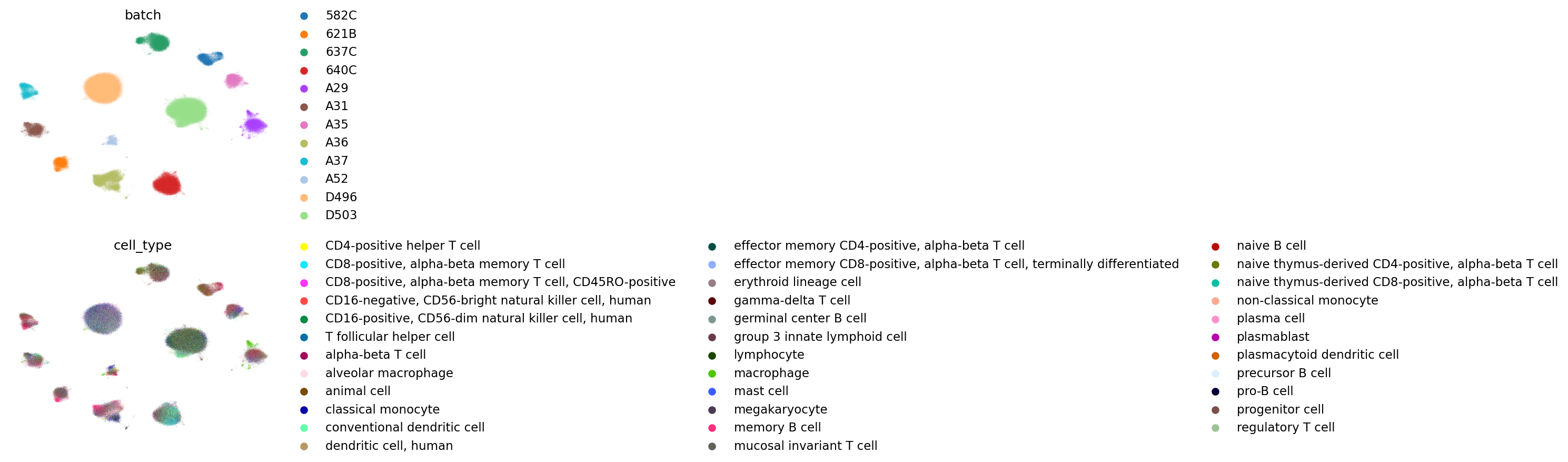
FADVI(un)_batch
[12]:
adata.write_h5ad('data/immune_atlas_benchmark.h5ad')
Benchmarking using scib_metrics
[13]:
bm = Benchmarker(
adata,
batch_key="batch",
label_key="cell_type",
embedding_obsm_keys=list(method_integration.keys()) + ["FADVI","FADVI(semi)","FADVI(un)"],
n_jobs=-1,
)
bm.benchmark()
/data/wliu12/miniconda3/envs/rnew/lib/python3.12/site-packages/scanpy/preprocessing/_pca/__init__.py:438: FutureWarning: Argument `use_highly_variable` is deprecated, consider using the mask argument. Use_highly_variable=True can be called through mask_var="highly_variable". Use_highly_variable=False can be called through mask_var=None
warn(msg, FutureWarning)
Computing neighbors: 100%|████████████████████████████████████████████████████████████████| 7/7 [09:32<00:00, 81.74s/it]
Embeddings: 0%| | 0/7 [00:00<?, ?it/s]
Metrics: 0%| | 0/10 [00:00<?, ?it/s]
Metrics: 0%| | 0/10 [00:00<?, ?it/s, Bio conservation: isolated_labels]
Metrics: 10%|████ | 1/10 [00:32<04:50, 32.23s/it, Bio conservation: isolated_labels]
Metrics: 10%|██▌ | 1/10 [00:32<04:50, 32.23s/it, Bio conservation: nmi_ari_cluster_labels_kmeans]
Metrics: 20%|█████▏ | 2/10 [00:37<02:11, 16.48s/it, Bio conservation: nmi_ari_cluster_labels_kmeans]
Metrics: 20%|███████▊ | 2/10 [00:37<02:11, 16.48s/it, Bio conservation: silhouette_label]
Metrics: 30%|███████████▋ | 3/10 [01:04<02:28, 21.18s/it, Bio conservation: silhouette_label]
Metrics: 30%|█████████████▊ | 3/10 [01:04<02:28, 21.18s/it, Bio conservation: clisi_knn]
Metrics: 40%|██████████████████▍ | 4/10 [01:05<01:20, 13.37s/it, Bio conservation: clisi_knn]
Metrics: 40%|████████████████████▍ | 4/10 [01:05<01:20, 13.37s/it, Batch correction: bras]E0923 13:17:40.389203 2708581 hlo_lexer.cc:443] Failed to parse int literal: 97330880669659612889
Metrics: 50%|█████████████████████████▌ | 5/10 [02:04<02:29, 29.81s/it, Batch correction: bras]
Metrics: 50%|███████████████████████ | 5/10 [02:04<02:29, 29.81s/it, Batch correction: ilisi_knn]
Metrics: 60%|███████████████████████████▌ | 6/10 [02:06<01:20, 20.11s/it, Batch correction: ilisi_knn]
Metrics: 60%|████████████████████████▌ | 6/10 [02:06<01:20, 20.11s/it, Batch correction: kbet_per_label]
Metrics: 70%|████████████████████████████ | 7/10 [23:48<21:57, 439.25s/it, Batch correction: kbet_per_label]
Metrics: 70%|█████████████████████████▏ | 7/10 [23:48<21:57, 439.25s/it, Batch correction: graph_connectivity]/data/wliu12/miniconda3/envs/rnew/lib/python3.12/site-packages/scib_metrics/metrics/_graph_connectivity.py:32: FutureWarning: pandas.value_counts is deprecated and will be removed in a future version. Use pd.Series(obj).value_counts() instead.
tab = pd.value_counts(comps)
Metrics: 80%|████████████████████████████▊ | 8/10 [23:50<10:00, 300.16s/it, Batch correction: graph_connectivity]
Metrics: 80%|████████████████████████████████ | 8/10 [23:50<10:00, 300.16s/it, Batch correction: pcr_comparison]
Embeddings: 14%|█████████▊ | 1/7 [23:55<2:23:31, 1435.18s/it]
Metrics: 0%| | 0/10 [00:00<?, ?it/s]
Metrics: 0%| | 0/10 [00:00<?, ?it/s, Bio conservation: isolated_labels]
Metrics: 10%|████ | 1/10 [00:57<08:37, 57.51s/it, Bio conservation: isolated_labels]
Metrics: 10%|██▌ | 1/10 [00:57<08:37, 57.51s/it, Bio conservation: nmi_ari_cluster_labels_kmeans]
Metrics: 20%|█████▏ | 2/10 [01:02<03:31, 26.49s/it, Bio conservation: nmi_ari_cluster_labels_kmeans]
Metrics: 20%|███████▊ | 2/10 [01:02<03:31, 26.49s/it, Bio conservation: silhouette_label]
Metrics: 30%|███████████▋ | 3/10 [01:29<03:08, 26.95s/it, Bio conservation: silhouette_label]
Metrics: 30%|█████████████▊ | 3/10 [01:29<03:08, 26.95s/it, Bio conservation: clisi_knn]
Metrics: 40%|██████████████████▍ | 4/10 [01:29<01:38, 16.35s/it, Bio conservation: clisi_knn]
Metrics: 40%|████████████████████▍ | 4/10 [01:29<01:38, 16.35s/it, Batch correction: bras]
Metrics: 50%|█████████████████████████▌ | 5/10 [01:32<00:57, 11.52s/it, Batch correction: bras]
Metrics: 50%|███████████████████████ | 5/10 [01:32<00:57, 11.52s/it, Batch correction: ilisi_knn]
Metrics: 60%|████████████████████████▌ | 6/10 [01:32<00:46, 11.52s/it, Batch correction: kbet_per_label]
Metrics: 70%|████████████████████████████ | 7/10 [21:19<15:19, 306.65s/it, Batch correction: kbet_per_label]
Metrics: 70%|█████████████████████████▏ | 7/10 [21:19<15:19, 306.65s/it, Batch correction: graph_connectivity]/data/wliu12/miniconda3/envs/rnew/lib/python3.12/site-packages/scib_metrics/metrics/_graph_connectivity.py:32: FutureWarning: pandas.value_counts is deprecated and will be removed in a future version. Use pd.Series(obj).value_counts() instead.
tab = pd.value_counts(comps)
Metrics: 80%|████████████████████████████▊ | 8/10 [21:19<07:30, 225.23s/it, Batch correction: graph_connectivity]
Metrics: 80%|████████████████████████████████ | 8/10 [21:19<07:30, 225.23s/it, Batch correction: pcr_comparison]
Embeddings: 29%|███████████████████▋ | 2/7 [45:14<1:51:58, 1343.77s/it]
Metrics: 0%| | 0/10 [00:00<?, ?it/s]
Metrics: 0%| | 0/10 [00:00<?, ?it/s, Bio conservation: isolated_labels]
Metrics: 10%|████ | 1/10 [00:14<02:14, 14.92s/it, Bio conservation: isolated_labels]
Metrics: 10%|██▌ | 1/10 [00:14<02:14, 14.92s/it, Bio conservation: nmi_ari_cluster_labels_kmeans]
Metrics: 20%|█████▏ | 2/10 [00:18<01:04, 8.01s/it, Bio conservation: nmi_ari_cluster_labels_kmeans]
Metrics: 20%|███████▊ | 2/10 [00:18<01:04, 8.01s/it, Bio conservation: silhouette_label]
Metrics: 30%|███████████▋ | 3/10 [00:32<01:17, 11.04s/it, Bio conservation: silhouette_label]
Metrics: 30%|█████████████▊ | 3/10 [00:32<01:17, 11.04s/it, Bio conservation: clisi_knn]
Metrics: 40%|████████████████████▍ | 4/10 [00:32<01:06, 11.04s/it, Batch correction: bras]
Metrics: 50%|█████████████████████████▌ | 5/10 [00:39<00:33, 6.75s/it, Batch correction: bras]
Metrics: 50%|███████████████████████ | 5/10 [00:39<00:33, 6.75s/it, Batch correction: ilisi_knn]
Metrics: 60%|████████████████████████▌ | 6/10 [00:39<00:26, 6.75s/it, Batch correction: kbet_per_label]
Metrics: 70%|████████████████████████████ | 7/10 [13:35<08:51, 177.20s/it, Batch correction: kbet_per_label]
Metrics: 70%|█████████████████████████▏ | 7/10 [13:35<08:51, 177.20s/it, Batch correction: graph_connectivity]/data/wliu12/miniconda3/envs/rnew/lib/python3.12/site-packages/scib_metrics/metrics/_graph_connectivity.py:32: FutureWarning: pandas.value_counts is deprecated and will be removed in a future version. Use pd.Series(obj).value_counts() instead.
tab = pd.value_counts(comps)
Metrics: 80%|████████████████████████████▊ | 8/10 [13:36<04:28, 134.45s/it, Batch correction: graph_connectivity]
Metrics: 80%|████████████████████████████████ | 8/10 [13:36<04:28, 134.45s/it, Batch correction: pcr_comparison]
Embeddings: 43%|█████████████████████████████▌ | 3/7 [58:51<1:13:32, 1103.18s/it]
Metrics: 0%| | 0/10 [00:00<?, ?it/s]
Metrics: 0%| | 0/10 [00:00<?, ?it/s, Bio conservation: isolated_labels]
Metrics: 10%|████ | 1/10 [00:14<02:12, 14.70s/it, Bio conservation: isolated_labels]
Metrics: 10%|██▌ | 1/10 [00:14<02:12, 14.70s/it, Bio conservation: nmi_ari_cluster_labels_kmeans]
Metrics: 20%|█████▏ | 2/10 [00:17<01:03, 7.89s/it, Bio conservation: nmi_ari_cluster_labels_kmeans]
Metrics: 20%|███████▊ | 2/10 [00:17<01:03, 7.89s/it, Bio conservation: silhouette_label]
Metrics: 30%|███████████▋ | 3/10 [00:32<01:16, 10.99s/it, Bio conservation: silhouette_label]
Metrics: 30%|█████████████▊ | 3/10 [00:32<01:16, 10.99s/it, Bio conservation: clisi_knn]
Metrics: 40%|██████████████████▍ | 4/10 [00:32<00:40, 6.69s/it, Bio conservation: clisi_knn]
Metrics: 40%|████████████████████▍ | 4/10 [00:32<00:40, 6.69s/it, Batch correction: bras]
Metrics: 50%|█████████████████████████▌ | 5/10 [00:34<00:25, 5.13s/it, Batch correction: bras]
Metrics: 50%|███████████████████████ | 5/10 [00:34<00:25, 5.13s/it, Batch correction: ilisi_knn]
Metrics: 60%|████████████████████████▌ | 6/10 [00:35<00:20, 5.13s/it, Batch correction: kbet_per_label]
Metrics: 70%|████████████████████████████ | 7/10 [14:07<10:25, 208.61s/it, Batch correction: kbet_per_label]
Metrics: 70%|█████████████████████████▏ | 7/10 [14:07<10:25, 208.61s/it, Batch correction: graph_connectivity]/data/wliu12/miniconda3/envs/rnew/lib/python3.12/site-packages/scib_metrics/metrics/_graph_connectivity.py:32: FutureWarning: pandas.value_counts is deprecated and will be removed in a future version. Use pd.Series(obj).value_counts() instead.
tab = pd.value_counts(comps)
Metrics: 80%|████████████████████████████▊ | 8/10 [14:08<05:06, 153.33s/it, Batch correction: graph_connectivity]
Metrics: 80%|████████████████████████████████ | 8/10 [14:08<05:06, 153.33s/it, Batch correction: pcr_comparison]
Embeddings: 57%|███████████████████████████████████████▍ | 4/7 [1:12:59<50:07, 1002.48s/it]
Metrics: 0%| | 0/10 [00:00<?, ?it/s]
Metrics: 0%| | 0/10 [00:00<?, ?it/s, Bio conservation: isolated_labels]
Metrics: 10%|████ | 1/10 [00:14<02:12, 14.70s/it, Bio conservation: isolated_labels]
Metrics: 10%|██▌ | 1/10 [00:14<02:12, 14.70s/it, Bio conservation: nmi_ari_cluster_labels_kmeans]
Metrics: 20%|█████▏ | 2/10 [00:18<01:07, 8.42s/it, Bio conservation: nmi_ari_cluster_labels_kmeans]
Metrics: 20%|███████▊ | 2/10 [00:18<01:07, 8.42s/it, Bio conservation: silhouette_label]
Metrics: 30%|███████████▋ | 3/10 [00:33<01:18, 11.27s/it, Bio conservation: silhouette_label]
Metrics: 30%|█████████████▊ | 3/10 [00:33<01:18, 11.27s/it, Bio conservation: clisi_knn]
Metrics: 40%|████████████████████▍ | 4/10 [00:33<01:07, 11.27s/it, Batch correction: bras]
Metrics: 50%|█████████████████████████▌ | 5/10 [00:35<00:27, 5.51s/it, Batch correction: bras]
Metrics: 50%|███████████████████████ | 5/10 [00:35<00:27, 5.51s/it, Batch correction: ilisi_knn]
Metrics: 60%|████████████████████████▌ | 6/10 [00:35<00:22, 5.51s/it, Batch correction: kbet_per_label]
Metrics: 70%|████████████████████████████ | 7/10 [12:51<08:22, 167.59s/it, Batch correction: kbet_per_label]
Metrics: 70%|█████████████████████████▏ | 7/10 [12:51<08:22, 167.59s/it, Batch correction: graph_connectivity]/data/wliu12/miniconda3/envs/rnew/lib/python3.12/site-packages/scib_metrics/metrics/_graph_connectivity.py:32: FutureWarning: pandas.value_counts is deprecated and will be removed in a future version. Use pd.Series(obj).value_counts() instead.
tab = pd.value_counts(comps)
Metrics: 80%|████████████████████████████▊ | 8/10 [12:52<04:14, 127.17s/it, Batch correction: graph_connectivity]
Metrics: 80%|████████████████████████████████ | 8/10 [12:52<04:14, 127.17s/it, Batch correction: pcr_comparison]
Embeddings: 71%|██████████████████████████████████████████████████ | 5/7 [1:25:52<30:38, 919.50s/it]
Metrics: 0%| | 0/10 [00:00<?, ?it/s]
Metrics: 0%| | 0/10 [00:00<?, ?it/s, Bio conservation: isolated_labels]
Metrics: 10%|████ | 1/10 [00:14<02:12, 14.69s/it, Bio conservation: isolated_labels]
Metrics: 10%|██▌ | 1/10 [00:14<02:12, 14.69s/it, Bio conservation: nmi_ari_cluster_labels_kmeans]
Metrics: 20%|█████▏ | 2/10 [00:17<01:02, 7.81s/it, Bio conservation: nmi_ari_cluster_labels_kmeans]
Metrics: 20%|███████▊ | 2/10 [00:17<01:02, 7.81s/it, Bio conservation: silhouette_label]
Metrics: 30%|███████████▋ | 3/10 [00:32<01:16, 10.95s/it, Bio conservation: silhouette_label]
Metrics: 30%|█████████████▊ | 3/10 [00:32<01:16, 10.95s/it, Bio conservation: clisi_knn]
Metrics: 40%|████████████████████▍ | 4/10 [00:32<01:05, 10.95s/it, Batch correction: bras]
Metrics: 50%|█████████████████████████▌ | 5/10 [00:34<00:26, 5.23s/it, Batch correction: bras]
Metrics: 50%|███████████████████████ | 5/10 [00:34<00:26, 5.23s/it, Batch correction: ilisi_knn]
Metrics: 60%|████████████████████████▌ | 6/10 [00:34<00:20, 5.23s/it, Batch correction: kbet_per_label]
Metrics: 70%|████████████████████████████▋ | 7/10 [04:10<02:33, 51.25s/it, Batch correction: kbet_per_label]
Metrics: 70%|█████████████████████████▉ | 7/10 [04:10<02:33, 51.25s/it, Batch correction: graph_connectivity]/data/wliu12/miniconda3/envs/rnew/lib/python3.12/site-packages/scib_metrics/metrics/_graph_connectivity.py:32: FutureWarning: pandas.value_counts is deprecated and will be removed in a future version. Use pd.Series(obj).value_counts() instead.
tab = pd.value_counts(comps)
Metrics: 80%|█████████████████████████████▌ | 8/10 [04:10<01:17, 38.99s/it, Batch correction: graph_connectivity]
Metrics: 80%|████████████████████████████████▊ | 8/10 [04:10<01:17, 38.99s/it, Batch correction: pcr_comparison]
Embeddings: 86%|████████████████████████████████████████████████████████████ | 6/7 [1:30:03<11:32, 692.25s/it]
Metrics: 0%| | 0/10 [00:00<?, ?it/s]
Metrics: 0%| | 0/10 [00:00<?, ?it/s, Bio conservation: isolated_labels]
Metrics: 10%|████ | 1/10 [00:17<02:35, 17.32s/it, Bio conservation: isolated_labels]
Metrics: 10%|██▌ | 1/10 [00:17<02:35, 17.32s/it, Bio conservation: nmi_ari_cluster_labels_kmeans]
Metrics: 20%|█████▏ | 2/10 [00:20<01:14, 9.26s/it, Bio conservation: nmi_ari_cluster_labels_kmeans]
Metrics: 20%|███████▊ | 2/10 [00:20<01:14, 9.26s/it, Bio conservation: silhouette_label]
Metrics: 30%|███████████▋ | 3/10 [00:38<01:30, 12.92s/it, Bio conservation: silhouette_label]
Metrics: 30%|█████████████▊ | 3/10 [00:38<01:30, 12.92s/it, Bio conservation: clisi_knn]
Metrics: 40%|██████████████████▍ | 4/10 [00:38<00:47, 7.86s/it, Bio conservation: clisi_knn]
Metrics: 40%|████████████████████▍ | 4/10 [00:38<00:47, 7.86s/it, Batch correction: bras]
Metrics: 50%|█████████████████████████▌ | 5/10 [00:46<00:40, 8.12s/it, Batch correction: bras]
Metrics: 50%|███████████████████████ | 5/10 [00:46<00:40, 8.12s/it, Batch correction: ilisi_knn]
Metrics: 60%|████████████████████████▌ | 6/10 [00:47<00:32, 8.12s/it, Batch correction: kbet_per_label]
Metrics: 70%|████████████████████████████ | 7/10 [08:23<05:59, 119.87s/it, Batch correction: kbet_per_label]
Metrics: 70%|█████████████████████████▏ | 7/10 [08:23<05:59, 119.87s/it, Batch correction: graph_connectivity]/data/wliu12/miniconda3/envs/rnew/lib/python3.12/site-packages/scib_metrics/metrics/_graph_connectivity.py:32: FutureWarning: pandas.value_counts is deprecated and will be removed in a future version. Use pd.Series(obj).value_counts() instead.
tab = pd.value_counts(comps)
Metrics: 80%|█████████████████████████████▌ | 8/10 [08:24<02:56, 88.13s/it, Batch correction: graph_connectivity]
Metrics: 80%|████████████████████████████████▊ | 8/10 [08:24<02:56, 88.13s/it, Batch correction: pcr_comparison]
Embeddings: 100%|██████████████████████████████████████████████████████████████████████| 7/7 [1:38:28<00:00, 844.06s/it]
[14]:
bm.plot_results_table()
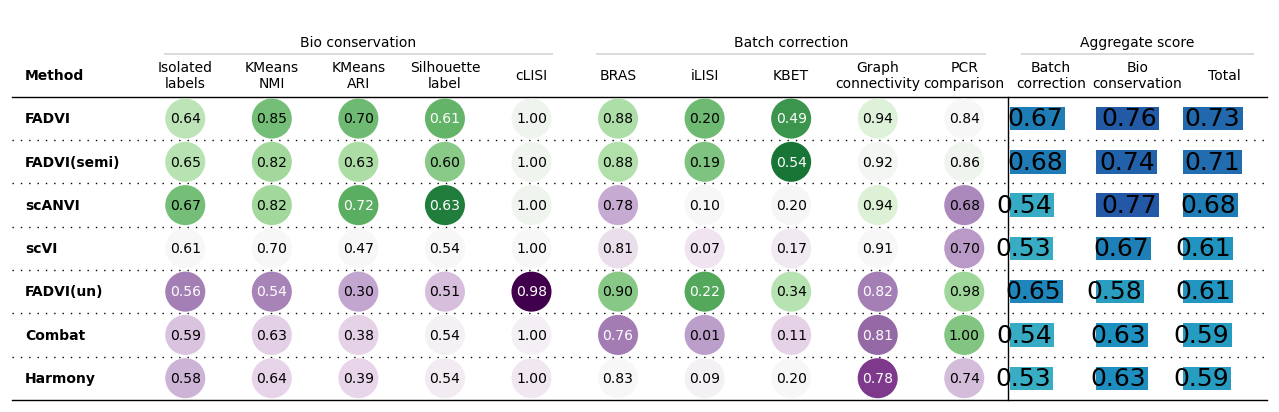
[14]:
<plottable.table.Table at 0x7a99c4236660>
[15]:
bm.get_results().to_csv('csv/immune_atlas_benchmark.csv')